Benchmarks¶
Settings¶
Machine¶
Ubuntu 22.04 instance on GitHub Actions
The benchmarking suits are implemented as GitHub Actions workflows.
According to profiling with
pyperf, each processor operates at a frequency between 2.4 and 3.3 GHz.
Tuning by the folloiwing settings:
All tests in a benchmarking suite are executed within the same GitHub Actions job. For more details, refer to Rodríguez-Guerra (2021).
CPU pinning to isolate the benchmarking process.
See the documentation of pyperf for more details on the following settings:
Stop
irqbalance.Set
/proc/irq/default_smp_affinityto3(CPU 0 and 1), where the benchmarking processes are pinned to CPU 2 and 3.Set
/proc/sys/kernel/perf_event_max_sample_rateto1./proc/sys/kernel/randomize_va_space= 2 (default)
Software¶
Python environment:
CPython 3.12.5 (64-bit)
Hash libraries:
mmh3 5.0.0-dev
python-xxhash 3.5.0
hashlib (Standard library)
md5is tested forlambda x: hashlib.md5(x).digest(), and so issha1. therefore, the results for these functions include the overhead of creating the hash object and a function call.
Benchmarking library:
pyperf 2.7.0
Used the bench_time_func interface to eliminate the overhead of the function call.
Processed time are measured by time.perf_counter() in nanoseconds.
Method¶
A benchmarking test is performed for each specified byte size, which is derived from the Fibonacci sequence.
For each input size, the test generates a set of 10
bytesinstances, where each instance’s size is pseudo-randomly selected from the range[ceil(input * 0.9), floor(input * 1.1)].This randomization is crucial as it increases the difficulty of branch predictions, creating a more realistic scenario. For further details, see xxHash: Performance comparison.
This inner loop of 10 iterations is repeated for a certain number of cycles, referred to as the outer loop, which is auto-calibrated by
pyperf.To avoid the overhead during the loop, iterators are pre-generated using
itertools.repeat()outside the loop. See Peters (2002) and the real code of thetimeitmodule in the Python Standard Library.The final result are measured using the median, as it is more robust than the mean, especially on untuned or unstable environments such as GitHub Actions. For more details, see pyperf: Analyze benchmark results.
Results¶
The resulting graphs are plotted using the pandas and matplotlib libraries.
Comparison of Version Improvements¶
JSON files containing the benchmark results are available at: hajimes/mmh3-benchmarks/results_basic-hash/2024-09-17_6bb9987

Figure 1: Latency for mmh3.hash() in version 4.1.0 and 5.0.0.
Smaller is better.¶
Comparison of Hash Functions Across Libraries¶
JSON files containing the benchmark results are available at: hajimes/mmh3-benchmarks/results/2024-09-17_30da46e
In the following graphs:
mmh32_32refers tommh3.mmh3_32_digest(). 32-bit output using 32-bit arithmetic. Developed in 2011.mmh3_128refers tommh3.mmh3_x64_128_digest(). 128-bit output using 64-bit arithmetic. Developed in 2011.xxh_32refers toxxhash.xxh32_digest(). 32-bit output using 32-bit arithmetic. Developed in 2014.xxh_64refers toxxhash.xxh64_digest(). 64-bit output using 64-bit arithmetic. Developed in 2014.xxh3_64refers toxxhash.xxh3_64_digest(). 64-bit output using vectorized arithmetic. Developed in 2020.xxh3_128refers toxxhash.xxh3_64_digest(). 128-bit output using vectorized arithmetic. Developed in 2020.md5refers tohashlib.md5(). 128-bit output using a cryptogprahic algorithm. Developed in 1992.sha1refers tohashlib.sha1(). 160-bit output using a cryptogprahic algorithm. Developed in 1995.
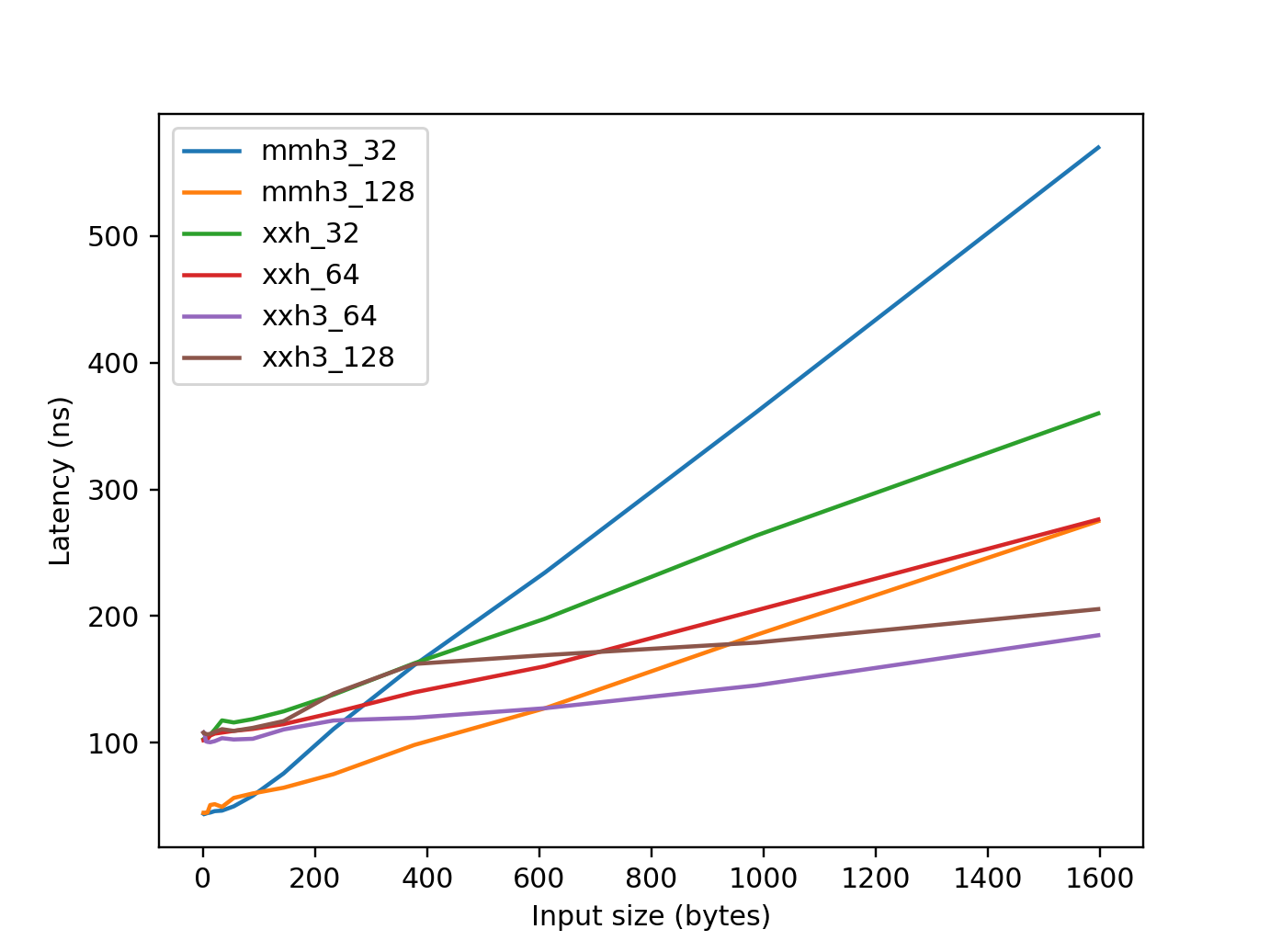
Figure 2: Latency for small data. Smaller is better.¶
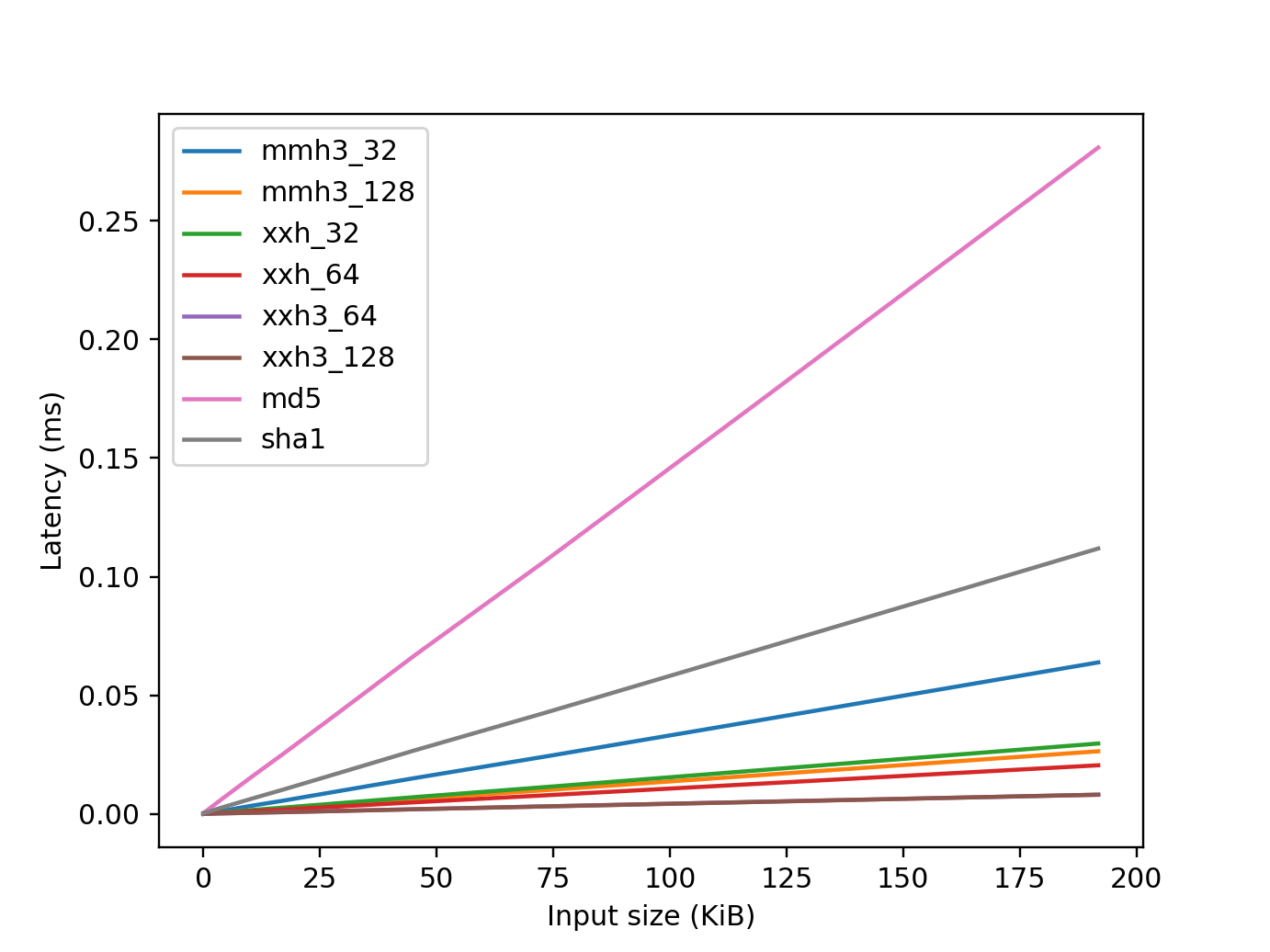
Figure 3: Latency for large data. Smaller is better.¶
The following graphs show the throughput, measured as the size of hash output generated per second by each function.
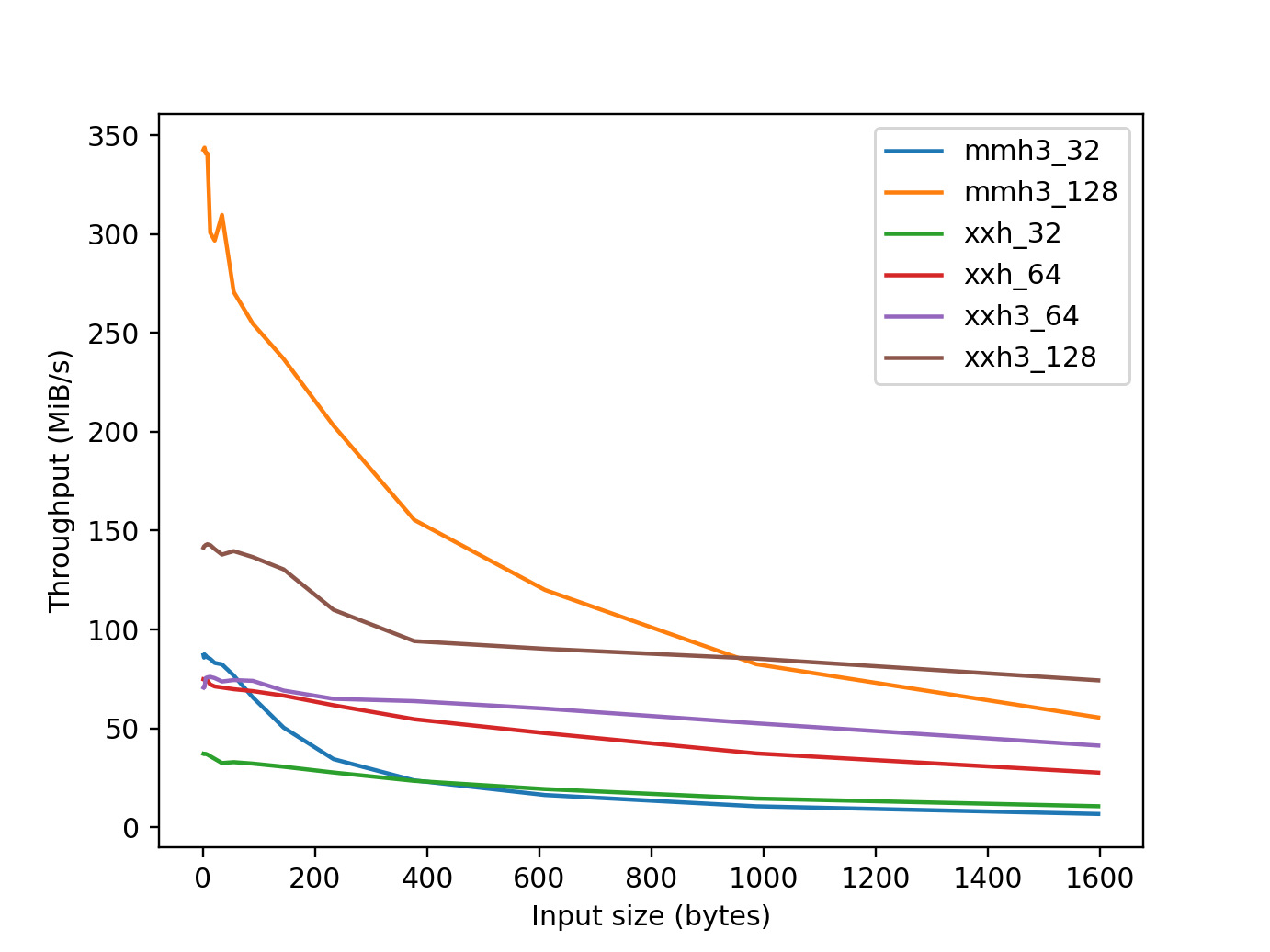
Figure 4: Throughput for small data. Larger is better.¶
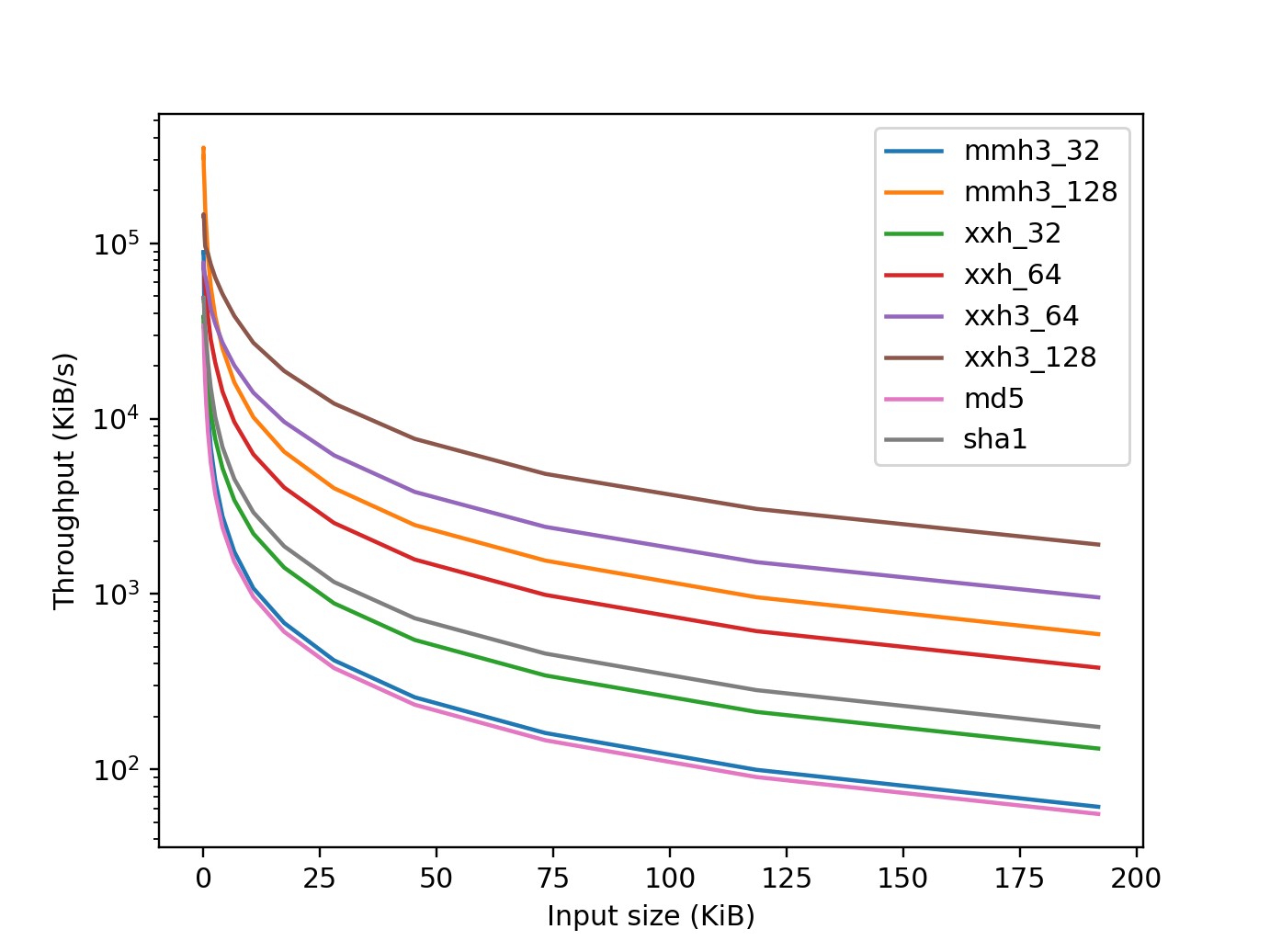
Figure 5: Throughput for large data. Larger is better. The y-axis is logscale.¶
Concluding Remarks¶
Version 5.0.0 of the mmh3 library has improved the performance of the
hash() function and other new functions by adopting
METH_FASTCALL.
This enhancement reduces the overhead of function calls. For data sizes
between 1–2 KB (such as 48x48 favicons), performance has improved by 10%–20%.
For smaller data (~500 bytes, like 16x16 favicons), performance increases by
approximately 30%. However, the performance gain from this revision remains
constant, meaning the relative improvement diminishes as data size increases.
When comparing hash functions across libraries, mmh3 5.0.0 is the most
performant for small data sizes, while the xxh3 families in xxhash 3.5.0
excel with larger data. This is largely due to the new version of mmh3
utilizing METH_FASTCALL, which reduces the overhead of function calls.
However, xxhash may adopt the same interface in the future, potentially
making this advantage temporary. To further improve mmh3 performance,
the core algorithm itself would need an overhaul.
Overall, these benchmarking results serve as a useful reference when selecting a hash function for your application, and they provide a solid foundation for future performance enhancements to our library.
References¶
Python Standard Library. timeit.
pyperf issues #1: Use a better measures than average and standard deviation #1.
Manuel Bernhardt. 2023. On pinning and isolating CPU cores.
Micha Gorelick and Ian Ozsvald. 2020. High Performance Python: Practical Performant Programming for Humans, 2nd ed. O’Reilly Media. ISBN: 978-1492055020. Chapter 2.
Tim Peters. 2002. Chapter 17. Algorithms: Introduction in Python Cookbook, 3rd ed. O’Reilly Media. ISBN: 978-0596001674.
Jaime Rodríguez-Guerra. 2021. Is GitHub Actions suitable for running benchmarks?.
Victor Stinner. 2016. My journey to stable benchmark, part 1 (system).
Victor Stinner. 2016. My journey to stable benchmark, part 3 (average).